目标:爬取零点看书网 一本小说
1、爬取小说目录地址 爬取小说地址:https://www.lingdiankanshu.co/258400/
查看网页源代码
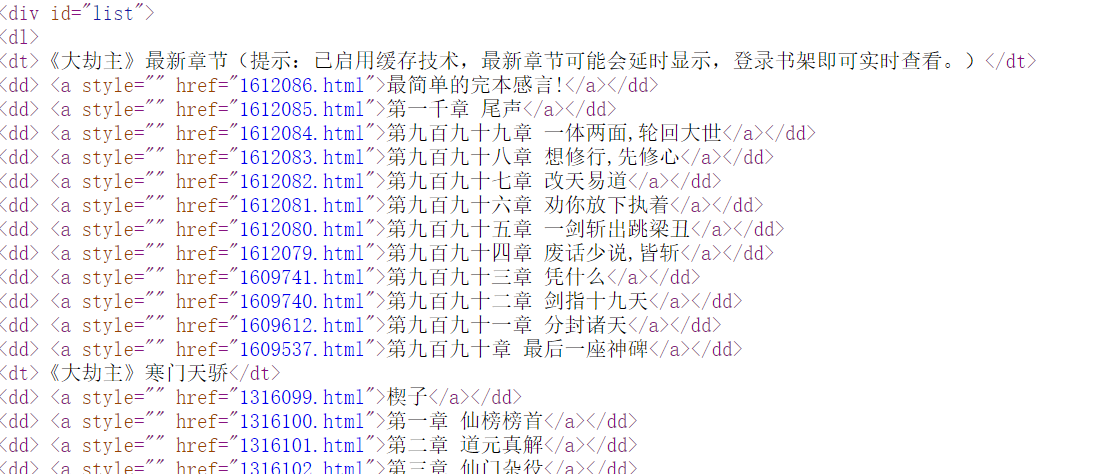
小说楔子在一个id等于list的div下的dl下第二个dt的同级标签dd的a标签里面
用xpath来获取
1 a_list = html.xpath('//div[@id="list"]/dl/dt[2]/following-sibling::dd/a' )
following-sibling :选取当前节点之后的所有同级节点
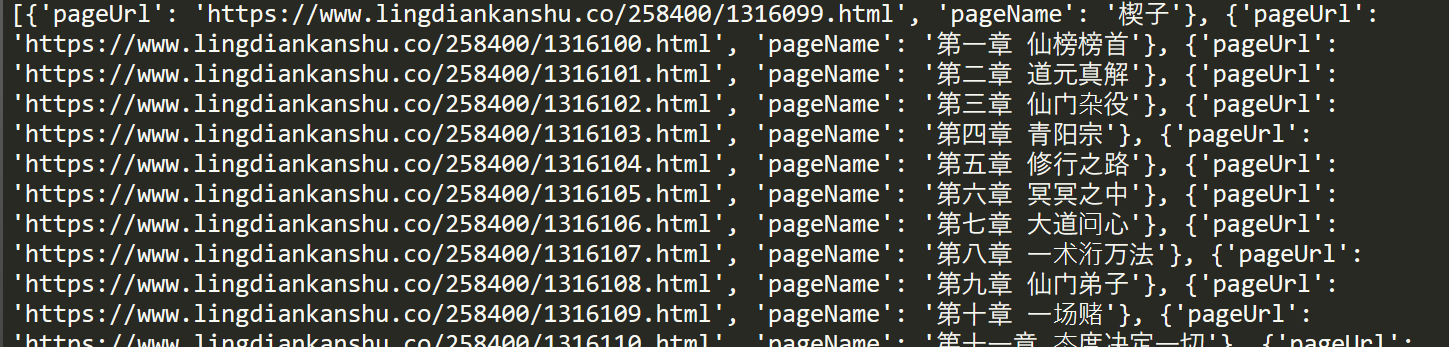
获取章节地址和章节名
1 2 3 4 5 6 7 pageUrlName_list = [] dit = {} for a in a_list: dit['pageUrl' ] = url + a.xpath('./@href' )[0 ] dit['pageName' ] = a.xpath('./text()' )[0 ] pageUrlName_list.append(dit.copy()) print (pageUrlName_list)
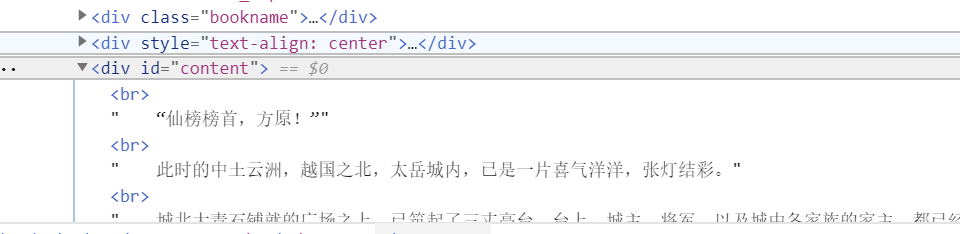
小说内容在一个id等于content的div里面
获取小说内容:
1 2 content_list = html.xpath('//div[@id="content"]/text()' ) print (content_list)
3、整理爬取的小说 1 2 content = '\r\n' .join(content_list[:-1 ]) print (content)
4、多线程下载 由于小说各个章节顺序一定,可以定义一个正在保存章节的标记
把章节地址扔进队列中,用的时候取出来
1 2 3 4 5 from queue import Queueq = Queue() for i, page in enumerate (pageUrlName_list): q.put([i, page])
当队列不为空时:从队列中取出一个元素
1 2 while not q.empty(): i, page_url_name = q.get()
判断当前爬取的章节是否和保存标记的章节数一样
不一样:等待
一样:保存当前章节,用来保存标记的章节数加一
1 2 3 if index == i: fw.write(content) index += 1
开始多线程:
1 2 3 4 5 6 7 8 ts = [] for i in range (10 ): t = Thread(target=down_txt, args=[q, fw]) t.start() ts.append(t) for t in ts: t.join()
5、完整代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 import requestsfrom lxml import etreefrom queue import Queuefrom threading import Threadheaders = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 Edg/81.0.416.72' , } def get_pageUrlName (url ): '''获取各章节地址和章节名''' resp = requests.get(url, headers=headers) html = etree.HTML(resp.text) dd_list = html.xpath('//div[@id="list"]/dl/dt[2]/following-sibling::dd' ) title = html.xpath('//h1/text()' )[0 ] pageUrlName_list = [] dit = {} for dd in dd_list: dit['pageUrl' ] = url + dd.xpath('./a/@href' )[0 ] dit['pageName' ] = dd.xpath('./a/text()' )[0 ] pageUrlName_list.append(dit.copy()) return pageUrlName_list, title def get_content (page_url ): '''获取内容''' resp = requests.get(page_url, headers=headers) html = etree.HTML(resp.text) content_list = html.xpath('//div[@id="content"]/text()' ) return '\r\n' .join(content_list[:-1 ]) def down_txt (q, fw ): '''保存小说''' global index while not q.empty(): i, page_url_name = q.get() page_url = page_url_name['pageUrl' ] page_name = page_url_name['pageName' ] content = page_name + get_content(page_url) print ('爬取-->' , page_name) while i > index: pass if index == i: print ('保存-->' , page_name) fw.write(content) index += 1 if __name__ == '__main__' : url = 'https://www.lingdiankanshu.co/467479/' pageUrl_list, title = get_pageUrlName(url) q = Queue() for i, page_url_name in enumerate (pageUrl_list): q.put([i, page_url_name]) index = 0 with open (f'{title} .txt' , 'w' , encoding='utf8' ) as fw: ts = [] for i in range (10 ): t = Thread(target=down_txt, args=[q, fw]) t.start() ts.append(t) for t in ts: t.join()
 2、爬取小说内容页
2、爬取小说内容页